
NN全连接神经网络
这是我第一次实现一个神经网络实例:使用python的Keras库来学习手写数字分类。
过程都写在注释里了,下面是train.py的代码:
1 | from tensorflow import keras |
可视化训练结果
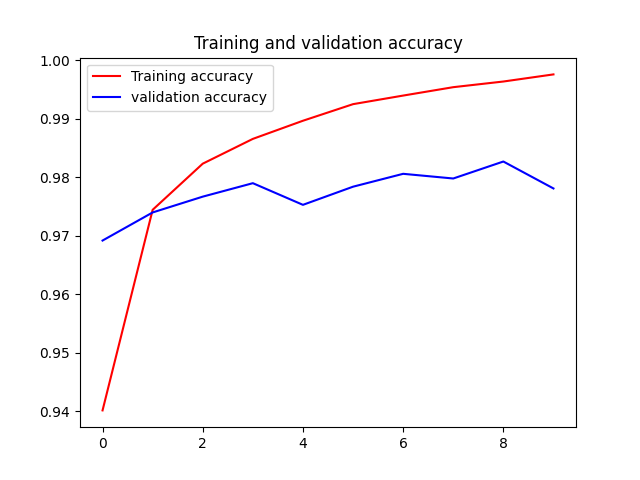
拟合结果基本很好
但发现测试精度比训练精度低不少,这是 过拟合 造成的
过拟合是指机器学习模型在新数据上的性能往往比在训练数据上要差
CNN卷积神经网络
train.py的代码:
1 | from tensorflow import keras |
模型信息:
1 | >>>model.summary() |
这是一个简单的卷积神经网络(Convolutional Neural Network,CNN)模型的结构概览。这个CNN模型用于处理28x28像素的灰度图像,并用于图像分类任务,目标是将输入的图像分为10个类别。
下面是对模型结构的解释:
输入层(InputLayer):
- 输入数据的形状为(None, 28, 28, 1),其中None表示输入的样本数量可以是任意值,28x28表示每个图像的尺寸,1表示输入图像是灰度图像(通道数为1)。
第一个卷积层(Conv2D):
- 使用32个大小为3x3的滤波器(卷积核)对输入图像进行卷积操作。
- 卷积操作会输出32个特征图(Feature Map)。
- 输出特征图的尺寸为(None, 26, 26, 32),因为卷积操作会在图像周围添加0像素(Padding),以便保持尺寸。
- 参数数量:32个滤波器 * (3x3的滤波器尺寸 * 1个输入通道 + 1个偏置项)= 320个参数。
第一个池化层(MaxPooling2D):
- 使用2x2的池化窗口对上一层的特征图进行最大池化操作。
- 最大池化会将特征图的尺寸减半,输出的特征图尺寸为(None, 13, 13, 32)。
- 池化层没有需要学习的参数。
第二个卷积层(Conv2D):
- 使用64个大小为3x3的滤波器对上一层的特征图进行卷积操作。
- 卷积操作会输出64个特征图。
- 输出特征图的尺寸为(None, 11, 11, 64)。
- 参数数量:64个滤波器 * (3x3的滤波器尺寸 * 32个输入通道 + 1个偏置项)= 18,496个参数。
第二个池化层(MaxPooling2D):
- 使用2x2的池化窗口对上一层的特征图进行最大池化操作。
- 最大池化会将特征图的尺寸减半,输出的特征图尺寸为(None, 5, 5, 64)。
- 池化层没有需要学习的参数。
第三个卷积层(Conv2D):
- 使用128个大小为3x3的滤波器对上一层的特征图进行卷积操作。
- 卷积操作会输出128个特征图。
- 输出特征图的尺寸为(None, 3, 3, 128)。
- 参数数量:128个滤波器 * (3x3的滤波器尺寸 * 64个输入通道 + 1个偏置项)= 73,856个参数。
展平层(Flatten):
- 将上一层的3D特征图展平为1D向量。
- 输出的形状为(None, 1152),其中1152是3x3x128的结果。
全连接层(Dense):
- 这是一个全连接层,包含10个神经元,用于输出10个类别的概率分布。
- 参数数量:1152个输入神经元 * 10个输出神经元 + 10个偏置项 = 11,530个参数。
总参数数量:320 + 18,496 + 73,856 + 11,530 = 104,202个参数。
这是一个典型的CNN模型结构,包含了交替的卷积层和池化层,最后是一个全连接层用于分类任务。在训练过程中,这些参数会根据数据进行调整,以使模型能够更好地对图像进行分类。
再来看看卷积模型的结构
1 | inputs = keras.Input(shape=(28, 28, 1)) |
来解释每一部分的作用:
输入层:
- 使用
keras.Input函数定义输入层,指定输入数据的形状为(28, 28, 1),其中28x28表示图像的尺寸,1表示输入图像是单通道的灰度图像。
- 使用
第一个卷积层和池化层:
layers.Conv2D定义了第一个卷积层,具有32个滤波器(即filters=32),滤波器的大小为3x3(即kernel_size=3)。- 激活函数使用ReLU(即
activation="relu"),它将对每个滤波器的输出应用ReLU非线性激活函数。 - 卷积层对输入进行卷积操作,输出特征图的大小为
(None, 26, 26, 32),其中None表示批量大小可以是任意值,26x26是因为卷积会在图像周围添加0像素(Padding)。 - 紧接着,
layers.MaxPooling2D定义了第一个池化层,使用2x2的池化窗口对特征图进行最大池化操作。这会将特征图的尺寸减半,输出的特征图大小为(None, 13, 13, 32)。
第二个卷积层和池化层:
layers.Conv2D定义了第二个卷积层,具有64个滤波器(即filters=64),滤波器的大小为3x3(即kernel_size=3)。- 激活函数使用ReLU(即
activation="relu")。 - 卷积层对上一层的特征图进行卷积操作,输出特征图的大小为
(None, 11, 11, 64)。 - 紧接着,
layers.MaxPooling2D定义了第二个池化层,使用2x2的池化窗口对特征图进行最大池化操作,输出的特征图大小为(None, 5, 5, 64)。
第三个卷积层:
layers.Conv2D定义了第三个卷积层,具有128个滤波器(即filters=128),滤波器的大小为3x3(即kernel_size=3)。- 激活函数使用ReLU(即
activation="relu")。 - 卷积层对上一层的特征图进行卷积操作,输出特征图的大小为
(None, 3, 3, 128)。
展平层:
layers.Flatten将卷积层的输出特征图展平为一维向量,用于连接到全连接层。- 输出的形状为
(None, 1152),其中1152是3x3x128的结果。
全连接层:
layers.Dense定义了全连接层,包含10个神经元,用于输出10个类别的概率分布。- 激活函数使用Softmax(即
activation="softmax"),用于将输出转换为类别概率。 - 输出的形状为
(None, 10),其中10是输出类别的数量。
模型构建:
keras.Model用于构建整个模型,指定输入层和输出层,形成完整的模型结构。
这个CNN模型有三个卷积层,每个卷积层后面都跟有一个最大池化层,然后是一个展平层和一个全连接层,最后输出10个类别的概率分布。这个模型用于图像分类任务,接受28x28大小的单通道灰度图像,并输出对应的图像类别概率。
最终的训练结果:
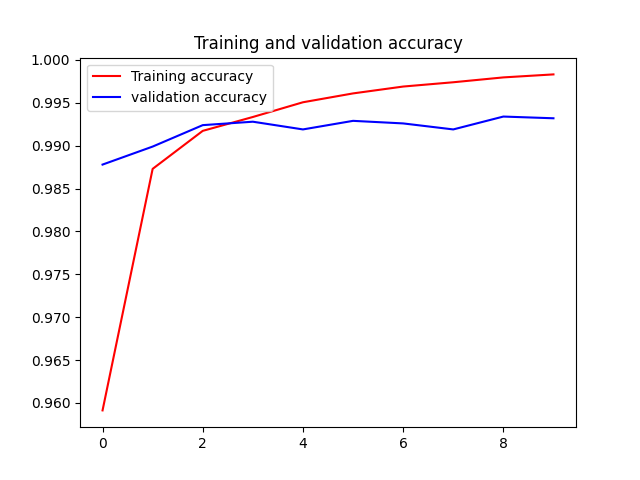
比上一种好很多,全连接模型测试精度约为97.8%,而这个简单的卷积神经网络的测试精度达到了99.1%,错误率降低了约60%(相对比例)
参考:Python深度学习(第二版)